이번 글에서는 자료형이라는 것에 대해서 알아보도록 하겠습니다.
자료형은 저번 글에서 변수를 설명할 때 잠깐 언급했었습니다.
먼저, 변수와 상수는 데이터를 담는 상자라고 설명했던 것 기억하시나요?
상자의 모양을 지정해주자
자료형은 이 상자들의 구체적인 모양을 정해주시는 거라고 생각하시면 됩니다.
무언가 물건을 담으려면 그 물건에 맞는 용기를 찾아서 넣어야겠죠?
예를 들어 물을 종이박스에 담을 순 없습니다. 상자는 다 젖고, 물은 다 흐를 테니 말이죠.
이처럼 프로그램 내에서도상자의 형태들을 데이터에 맞게 명확하게 지시해주어야 합니다.
이런 자료형들은 언어들마다 조금씩 차이는 있지만 기본적인 구조는 비슷합니다.
먼저, 자료형은 정수형과 실수형으로 나뉩니다.
그리고 이 두 가지에서 다시 크기에 따라서 여러 종류로 나뉘게 되는데,
표를 통해서 확인해봅시다.
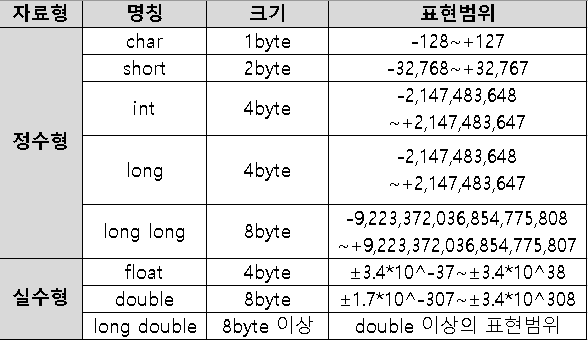
일단 자료형의 크기는 바이트(byte) 단위로 표시되는데, 1바이트는 8비트이며
1바이트는 0부터 2의 8 제곱 -1까지의 숫자를 표현할 수 있습니다.
2바이트는 2의 16 제곱 -1 10바이트는 2의 80 제곱 -1까지의 숫자를 표현할 수 있는 것입니다.
그럼 이제 char라는 자료형부터 한번 보도록 할까요?
char는 character의 약자이며 표현 범위는 -(2의 7 제곱)~2의 7제곱 -1인걸 볼 수 있습니다.
그런데 아까 1바이트는 2의 8 제곱-1까지의 숫자를 표현할 수 있다고 했는데, 어떻게 된 걸까요?
이는 바로 음수를 표현해야 하기 때문입니다.
2진수로 숫자를 표현하는 경우 가장 왼쪽 비트, 즉 최상위 비트(MSB)는 부호 비트로 사용됩니다.
이 값이 0이냐, 1이냐에 따라서 해당 2진수가 음수인지, 양수인지 판단하는 것입니다.
때문에 1바이트는 실제로 -(2의 7 제곱)~2의 7제곱 -1까지의 숫자를 표현할 수 있는 것입니다.
-1이 붙는 이유는 양수에 0을 포함하고 있기 때문입니다.
이때 자료형의 예약어, char의 앞에 unsigned를 적어주시게 되면,
최상위 부호 비트를 값을 표현하는 비트로 사용할 수 있게 됩니다.
그러면 해당 2진수는 양수만 표현할 수 있게 되고,
1바이트의 경우 온전히 2의 8 제곱 -1의 숫자를 표현할 수 있게 됩니다.
문자는 어떻게?
그런데 위에서 자료형을 크게 분류할 때, 정수형과 실수형으로 분류했었습니다.
그러면 문자는 어떻게 저장해야 하는지 당연히 의문이 들 수 있습니다.
이에 관해선 걱정한 필요가 전혀 없는데, C언어에선 char자료형을 사용해 문자를 표현하기 때문입니다.
이렇게 하는 이유를 알기 위해선 먼저 아스키코드라는 것에 대해서 알아야 합니다.
아스키코드는 0부터 127까지의 숫자를 영문과, 특수문자, 전자신호로 1:1 대응시켜놓은 것입니다.
그리고 이제 다시 char자료형을 보시면 최대 127까지 표현할 수 있는 것을 볼 수 있습니다.
이제 조금 감이 오시나요?
이 둘의 크기가 똑같기 때문에 C언어에선 char자료형을 사용해서 문자를 표현합니다.
예를 들어 char자료형에 'a'라는 문자를 저장하면, 이 값은 97과 동일합니다.
또한 영문은 저장할 때 1바이트, 한글은 2바이트가 필요하다는 사실도 기억해두시길 바랍니다.
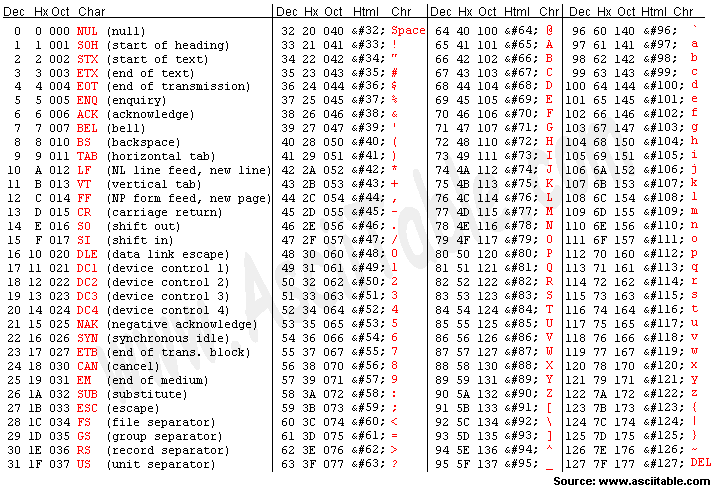
위는 인터넷에서 찾아온 아스키코드표입니다.
Dec는 10진수 Hx는 16진수 Oct는 8진수, char가 대응되는 문자입니다.
또한 아까 숫자와 문자뿐만이 아닌 전자신호와도 1:1로 대응된다고 말했었는데,
SOH, STX 등등이 이 전자신호이며 옆의 괄호 안에 어떠한 신호인지 적혀있습니다.
이제 코드를 통해 자료형을 실제로 사용해보겠습니다.
#include<stdio.h>
#include<limits.h>
#include<float.h>
int main() {
char word = CHAR_MAX;
short f_num = SHRT_MAX;
int sec_num = INT_MAX;
long t_num = LONG_MAX;
long long four_num = LLONG_MAX;
float fif_num = FLT_MAX;
double six_num = DBL_MAX;
long double sev_num = LDBL_MAX;
printf("자료형의 크기, 최댓값\n");
printf("char : %d, %d\n", sizeof(char), word);
printf("short : %d, %d\n", sizeof(short), f_num);
printf("int : %d, %d\n", sizeof(int), sec_num);
printf("long : %d, %ld\n", sizeof(long), t_num);
printf("long long : %d, %lld\n", sizeof(long long), four_num);
printf("float : %d, %f\n", sizeof(float), fif_num);
printf("double : %d, %lf\n", sizeof(double), six_num);
printf("long double : %d, %lf\n", sizeof(long double), sev_num);
printf("\n");
word += 1;
f_num += 1;
sec_num += 1;
t_num += 1;
four_num += 1;
fif_num *= 1000;
six_num *= 1000;
sev_num *= 1000;
printf("자료형의 크기, 최댓값\n");
printf("char : %d, %d\n", sizeof(char), word);
printf("short : %d, %d\n", sizeof(short), f_num);
printf("int : %d, %d\n", sizeof(int), sec_num);
printf("long : %d, %ld\n", sizeof(long), t_num);
printf("long long : %d, %lld\n", sizeof(long long), four_num );
printf("float : %d, %f\n", sizeof(float), fif_num);
printf("double : %d, %lf\n", sizeof(double), six_num);
printf("long double : %d, %lf\n", sizeof(long double), sev_num);
}이 코드는 각각의 자료형들로 변수를 선언하고, 그 자료형의 크기와 최댓값을 입력해 출력합니다.
그리고 그 값에 숫자를 더해서 최댓값을 넘어가는 경우를 확인하는 코드입니다.
먼저 변수들을 초기화할 때 입력한 INT_MAX, LONG_MAX 등은 그 자료형의 최댓값이 저장된 상수입니다.
이 상수들을 사용하기 위해선 정수형은 #include <limits.h>, 실수형은 #include <float.h> 헤더를
선언해주셔야 합니다. 헤더가 무엇인지에 대해서는 추후에 설명하도록 하겠습니다.
실제 실행화면은 다음과 같습니다.
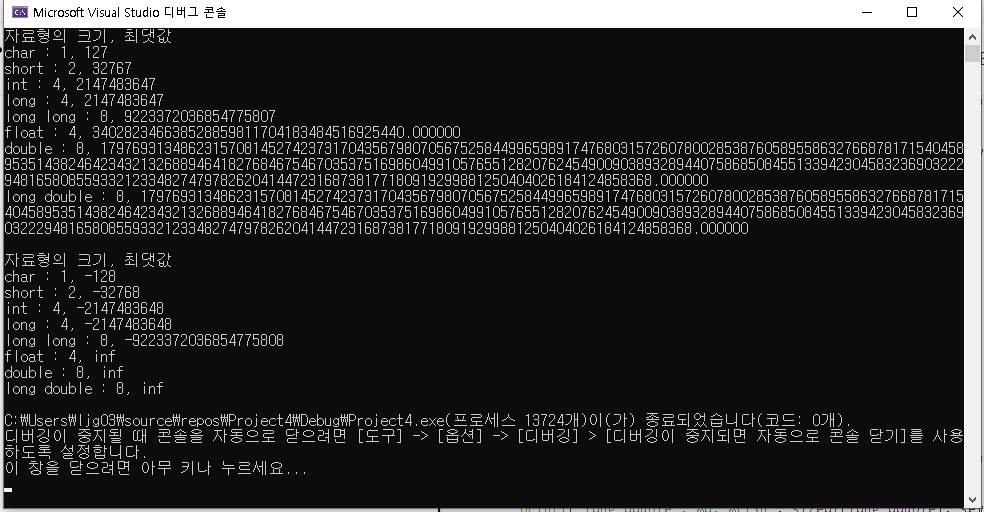
실행화면을 보시면 자료형의 크기가 바이트 단위로 표시되고, 그 자료형의 최댓값이
그 옆에 표시되는 것을 볼 수 있습니다.
그리고 두 번째 출력에선 자료형의 크기는 동일한데 뒤의 값들이 바뀌어있습니다.
정수형은 음수가 되어있고, 실수형은 inf가 출력되어있는데, 이게 대체 어떻게 된 걸까요?
사실 결과를 자세히 보시면 정수형들의 값이 해당 자료형의 최솟값이란 걸 알 수 있습니다.
(참고로 inf의 경우는 Infinite의 약자입니다.)
이러한 현상이 발생하는 이유는 변수에 값을 더하는 과정에서 오버플로가 일어났기 때문에,
값이 최댓값에서 다시 최솟값으로 넘어가게 된 것입니다.
오버플로? 언더플로?
예를 들어 4비트로 이루어진 2 진수 값 0111이 있다고 가정해봅시다.
여기서 가장 왼쪽의 최상위 비트(MSB)는 부호 비트로써 0이면, 양수, 1이면 음수가 됩니다.
그리고 나머지 비트가 값을 표현하는데, 2진수 0111은 10진수로 변경했을 때
2의 0 제곱 + 2의 1 제곱 + 2의 2 제곱 이기 때문에 값이 7이 됩니다.
그런데 여기서 2 진수 값에 1을 더한다고 생각해봅시다.
2진수의 경우 값이 2가 되면 올림수가 생기기 때문에 2진수의 값은 1000이 돼버립니다.
그러면 이 2진수는 값을 표현하는 오른쪽 3비트를 넘어서 부호 비트를 침범합니다.
이로 인해 데이터의 값이 1000이 되어버리고, 이는 10진수로 -8입니다.
이러한 현상을 바로 오버플로라고 이야기하며, 이 때문에 최댓값을 넘어가게 되면
다시 값이 최솟값으로 돌아가 시작하는 것입니다.
이러한 정수형의 특성을 그림으로 표현하면 다음과 같습니다.

이처럼 정수형들은 값들이 계속 순환하는 원형으로 이루어져 있다고 볼 수 있습니다.
또한 최솟값에서 값을 빼도 동일하게 자료형의 최댓값에서부터 감소시키고, 이를 언더플로라고 합니다.
시험 삼아 위의 코드에서 정수에 값을 곱해보기도 하고 빼기도 해 보시길 바랍니다.
그런데 왜 실수형은 inf로 표시되느냐?
이것은 정수형과 실수형은 구조 자체가 다르기 때문인데요, 이를 지금 설명하기엔 너무 길어 지기 때문에
이렇다는 사실만 알아두시길 바랍니다.
이상으로 C언어의 자료형에 대한 설명은 마치도록 하겠습니다.
도움이 되셨다면 좋겠고, 다음 글에선 연산자에 대해서 알아보도록 하겠습니다.
감사합니다.

'프로그래밍 언어 > C언어' 카테고리의 다른 글
| C언어 5. 입출력 (0) | 2020.07.10 |
|---|---|
| C언어 4. 연산자 (0) | 2020.07.10 |
| C언어 2. 변수, 상수 (0) | 2020.07.09 |
| C언어 1. 개발 툴 설치 (0) | 2020.07.09 |
| C언어 개요 (1) | 2020.07.09 |