이번 글에선 전처리와 분할 컴파일에 대해 알아보도록 하겠습니다.
저희가 지금까지 코드를 작성할 때, 언제나 작성했던 #include <stdio.h>가 무엇인지
드디어 그 의미를 알 수 있을것입니다.
전처리
먼저 전처리에 대해 설명할 텐데, 기억하실지 모르겠지만 개발 툴 설치 때 잠깐 이야기했던
컴파일 과정에서 전처리에 대해서 한번 언급했었습니다.
컴파일러는 컴파일 시 전처리 과정을 거치게 되는데, 이 전처리 과정시에
#으로 시작되는 명령들만 따로 실행하게 됩니다. 이들은 전처리 명령어라고 합니다.
그럼 전처리 명령어엔 어떤 것들이 있는지 알아봅시다.
먼저 우리가 언제나 사용했던 include에 대해 알아봅시다.
include는 사전에서 포함시키다 라는 뜻을 가지고 있는데요,
말 그대로 자신이 원하는 파일을 특정 디렉토리에서 찾아서 프로그램에 포함시키는 것을 의미합니다.
사용법은 #include <파일 이름>또는 #include "파일 이름"과 같이 사용합니다.
이 둘의 차이점은 파일을 포함할 경로를 지정하는 부분에 있습니다.
꺽쇠 괄호의 경우엔 컴파일러에 설정된 특정 디렉토리에서 파일을 찾는데,
이곳에 주로 표준 라이브러리 함수를 사용할 때 필요한 헤더 파일들이 모여있습니다.
헤더 파일이란 stdio.h와 같은 파일들을 말합니다.
큰따옴표의 경우엔 포함시킬 파일을 먼저 현재 작업 디렉토리(소스파일이 저장된 폴더)에서 찾고,
해당 폴더에 파일이 존재하지 않으면 꺽쇠 괄호와 동일한 경로에서 다시 찾습니다.
이는 주로 프로그래머가 임의로 작성한 헤더 파일을 포함하려 할 때 사용합니다.
또한 다른 디렉토리에 있는 파일을 사용하려면, 해당 디렉토리의 경로를 지정해주면 됩니다.
(예: #include"C:\Clanguage\mheader.h")
헤더 파일은 왜 써야 할까?
그럼 이러한 헤더 파일을 왜 사용하는 것일까요?
헤더파일을 사용하면 프로그램을 깔끔하고 편리하게 작성 할 수 있기 때문입니다.
만약 C언어에 헤더 파일이 존재하지 않는다면
여러분은 printf, scanf등등 표준 라이브러리에 포함된 함수들을 매번 구현해서 사용해야 할 것입니다.
또한 파일 구조체와 같은 경우에도 동일할 것입니다.
때문에 이렇게 빈번하게 사용되는 함수, 구조체, 변수 등을 헤더 파일에 선언해놓고
이를 파일로 만들어 필요할 때마다 가져와서 사용하는 것입니다.
그럼 이제 헤더 파일을 직접 작성해서 사용해보도록 하겠습니다.

헤더 파일의 경우 위와 같이 헤더 파일에서 추가를 통해 자신이 헤더 파일을 만들어서 사용할 수 있습니다.

헤더 파일이 만들어지는 경로는 위에서 말했듯이 소스파일이 있는 폴더입니다.
typedef struct{
char *name;
int age;
}Student;
void exchangeStd(Student *s1, Student *s2) {
Student tmp;
tmp = *s1;
*s1 = *s2;
*s2 = tmp;
}위와 같이 헤더 파일을 만들어보도록 합시다.
위의 구조체 선언 부분에서 구조체 관련 글에서 알아본 typedef를 사용하는데,
typedef struct{멤버}구조체명 형태로 작성하여 사용할 수도 있으니 기억해두시면 유용합니다.
그러면 이제 이 헤더 파일을 포함시키면 소스코드에서 따로 구현하지 않고도
위에서 작성한 구조체와 함수를 사용할 수 있을 것입니다.
#include <stdio.h>
#include"mheader.h"
int main() {
Student s1 = { "홍길동", 18 };
Student s2 = { "장발장", 17 };
printf("s1 -> 이름 : %s, 나이 : %d\n", s1.name, s1.age);
printf("s2 -> 이름 : %s, 나이 : %d\n", s2.name, s2.age);
exchangeStd(&s1, &s2);
printf("s1 -> 이름 : %s, 나이 : %d\n", s1.name, s1.age);
printf("s2 -> 이름 : %s, 나이 : %d\n", s2.name, s2.age);
}
이렇게 헤더 파일을 포함시켜 주시면 전처리 후에 소스파일이 다음과 같이 바뀝니다.
typedef struct {
char* name;
int age;
}Student;
void exchangeStd(Student* s1, Student* s2) {
Student tmp;
tmp = *s1;
*s1 = *s2;
*s2 = tmp;
}
int main() {
Student s1 = { "홍길동", 18 };
Student s2 = { "장발장", 17 };
printf("s1 -> 이름 : %s, 나이 : %d\n", s1.name, s1.age);
printf("s2 -> 이름 : %s, 나이 : %d\n", s2.name, s2.age);
exchangeStd(&s1, &s2);
printf("s1 -> 이름 : %s, 나이 : %d\n", s1.name, s1.age);
printf("s2 -> 이름 : %s, 나이 : %d\n", s2.name, s2.age);
return 0;
}이러한 과정을 통해서 우리는 지금까지 stdio.h헤더 파일에 작성되어 있는
printf등과 같은 표준 라이브러리 함수를 사용하고 있었던 것입니다.
define으로 기호화하자
다음은 define에 대해서 알아보도록 하겠습니다.
define명령어는 상수나 문장을 자신이 정한 의미 있는 단어로 사용할 수 있도록 하는 명령어입니다.
바로 코드로 확인해보도록 합시다.
#include <stdio.h>
#define PI 3.14
int main() {
int rad = 10;
printf("반지름 : %d, 원주율 : %f, 원의 둘레 : %f", rad, PI, 2 * rad * PI);
return 0;
}위의 코드는 원의 둘레를 구하는 코드인데,
원주율 3.14를 define을 사용해서 PI로 사용할 수 있도록 해서 작성했습니다.
이때 PI를 매크로명, 실제 값인 3.14를 확장 문자열이라고 이야기합니다.
매크로명은 관례상 대문자로 적어주고, 확장 문자열과 매크로명 사이에 하나 이상의 공백을 두고 적습니다.
상수만이 아닌 문자열도 치환 가능하니 직접 작성해보시길 바랍니다.
다음은 define을 사용해 함수를 작성하는 법에 대해 알아보겠습니다.
이때는 #define 매크로 함수명(전달 인자) 확장 문자열 과 같은 형태로 작성해주시면 되는데,
코드로 한번 확인해보겠습니다.
#include <stdio.h>
#define SUMMY(x, y) x+y
int main() {
printf("%d", SUMMY(10, 10));
return 0;
}위처럼 작성해주시면 define을 통해 두 숫자를 더하는 작업을
SUMMY(인자1,인자2)의 형태로 사용할 수 있습니다.
물론 이는 매우 간단한 예이고, 다른 함수를 구현할 수도 있을 것입니다.
이런 define을 사용한 치환을 통해 좀 더 가독성이 높은 코드를 작성할 수 있습니다.
조건부 컴파일
다음은 조건부 컴파일 전처리 명령어에 대해 알아보도록 하겠습니다.
조건부 컴파일이란 코드를 자신이 정한 조건에 따라 선택적으로 컴파일할 수 있도록 하는 것입니다.
이때 사용되는 명령어는 #if, #else, #elif, #ifdef, #ifndef, #endif등이 있습니다.
#if, #else, #elif의 경우 우리가 사용하는 if문과 기본적인 구조는 똑같습니다.
주의할 점은 조건식에 괄호가 필요 없으며, 보통 조건식을 매크로의 값 즉 #define의 값과 비교합니다.
조건식 비교대상은 상수만 가능하며 실수, 문자열은 사용할 수 없습니다.
또한 마지막에 #endif를 사용해 끝을 표시해주셔야 합니다.
#include <stdio.h>
#define NUM 3
int main() {
#if NUM <= 5
printf("NUM <= 5");
#elif NUM > 5
printf("NUM > 5");
#endif
return 0;
}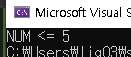
이처럼 작성해주시면 NUM의 값에 따라 코드를 부분적으로 컴파일하여 실행합니다.
위에선 NUM의 값이 3이기 때문에 NUM <= 5 조건을 만족해서
printf("NUM <= 5");가 실행된 것을 볼 수 있습니다.
#ifdef의 경우 #ifdef 매크로명과 같은 형태로 사용하는데,
지정해놓은 매크로명이 #define으로 작성되어 있을 경우 코드를 컴파일합니다.
또한 #ifdef와 #elif, #else를 같이 사용할 수 있습니다.
#ifndef는 반대로 매크로명이 존재하지 않으면 코드를 컴파일합니다.
#ifdef와 #ifndef모두 #if처럼 끝에 #endif를 작성해주셔야 합니다.
#include <stdio.h>
#define NUM 3
#define NUM2 5
int main() {
#ifdef NUM
printf("NUM = %d", NUM);
#elif NUM2
printf("NUM2 = %d", NUM2);
#endif
return 0;
}
이처럼 작성해주시면 코드에 NUM매크로가 작성되어 있을 경우 printf("NUM = %d", NUM);를
컴파일합니다.
위의 조건을 충족하면 else if와 동일하게 NUM2가 정의되어 있더라도 해당 코드는 컴파일하지 않습니다.
조건부 컴파일은 프로그램의 호환성은 높이는데 큰 도움을 줍니다.
C언어의 기본적인 문법은 같아도 컴파일러의 버전, 종류에 따라서
자료형의 크기나 라이브러리 함수가 다를 수 있습니다.
때문에 그런 상황에서 모두 컴파일 가능하도록 코드를 작성하여 프로그램의 호환성을 높일 수 있습니다.
이번 글은 이 정도로 마치고, 다음 글에서 이어서 설명하도록 하겠습니다.
감사합니다.

'프로그래밍 언어 > C언어' 카테고리의 다른 글
| C언어 21. 전처리와 분할 컴파일-2 (0) | 2020.07.28 |
|---|---|
| C언어 19. 파일 입출력-2 (0) | 2020.07.24 |
| C언어 18. 파일 입출력-1 (0) | 2020.07.23 |
| C언어 17. 응용자료형 (0) | 2020.07.23 |
| C언어 16. 변수의 영역 (0) | 2020.07.22 |